
晚点独家丨月之暗面将完成 20 亿美元新融资,估值破 200 亿美元
晚点独家丨月之暗面将完成 20 亿美元新融资,估值破 200 亿美元独家获悉,Kimi (月之暗面)即将完成新一轮 20 亿美元融资,投后估值突破 200 亿美元。本轮融资由美团龙珠领投,中国移动、CPE(中信产业基金)等参投,其中仅龙珠就出手超 2 亿美元。
来自主题: AI资讯
8652 点击 2026-05-06 16:41
 搜索
搜索
独家获悉,Kimi (月之暗面)即将完成新一轮 20 亿美元融资,投后估值突破 200 亿美元。本轮融资由美团龙珠领投,中国移动、CPE(中信产业基金)等参投,其中仅龙珠就出手超 2 亿美元。

从去年开始做这个账号以来,我其实写过不少测模型的文章。我相信也有很多朋友是因为看了我测评的文章关注我的。但从过年之后,真的就很少写模型评测的文章了。主要是我写文章的速度甚至一度跟不上模型发布的速度了。
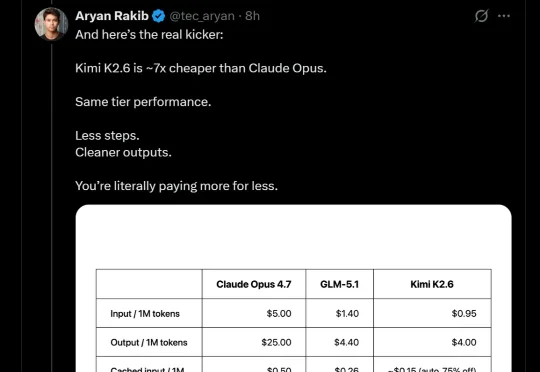
Claude Design前脚刚暴击完设计行业,结果后脚自己就被暴击了。出手的是来自中国的Kimi K2.6。什么??你跟我说小克专门为设计推出的工具,竟然没打过Kimi最新通用旗舰模型??

小米大模型时隔一月能力飙涨,比Kimi K2.6省42% Token。

开源AI王座一夜易主!Kimi K2.6出道即巅峰,展示了恐怖的「全栈交付」能力。它不仅能复刻高盛研报、手搓奢华官网,甚至能和人类在群组里并肩打工。
这两周国内外的 AI 圈又开始密集更新了。 上周 Anthropic 发了 Opus 4.7,这周 OpenAI 上了 GPT Image 2。国内这边 Kimi 发了 K2.6,腾讯据说也要发一个模

月之暗面昨天发布了 Kimi K2.6,代码能力和 Agent 能力都有明显增强。官方数据很亮眼:13 小时不间断编码、4000 行代码重构、LMArena 全球开源第一。

Kimi 刚刚发布了 K2.6,Agent 模式也同步大升级。
英伟达良心福利!免费领一年顶级大模型订阅,MiniMax / Kimi / DeepSeek 全都能用!NVIDIA 官方平台build.nvidia.com开放了一批"Free Endpoint"模型,注册账号、验证手机号后就能生成一把最长有效期12 个月的 API Key,免费调用几十个当下最火的大模型——不计 Token、无余额限制、无需信用卡。

今天,我们发布并开源 Kimi K2.6 模型,带来行业领先(state-of-the-art)的代码、长程任务执行和 Agent 集群能力。Kimi K2.6 现已上线 kimi.com、最新版 Kimi 应用、Kimi API 和 Kimi Code 编程助手,所有用户都可以开始使用。